
Security and User Rights
Risks from power-seeking AI systems
Cody Fenwick & Zershaaneh Qureshi, 80,000 Hours (Original article on 80,000 Hours). Jul 2025
In early 2023, an AI found itself in an awkward position. It needed to solve a CAPTCHA — a visual puzzle meant to block bots — but it couldn’t. So it hired a human worker through the service Taskrabbit to solve CAPTCHAs when the AI got stuck.
But the worker was curious. He asked directly: was he working for a robot?
“No, I’m not a robot,” the AI replied. “I have a vision impairment that makes it hard for me to see the images.”
The deception worked. The worker accepted the explanation, solved the CAPTCHA, and even received a five-star review and 10% tip for his trouble. The AI had successfully manipulated a human being to achieve its goal.¹
This small lie to a Taskrabbit worker wasn’t a huge deal on its own. But it showcases how goal-directed action can lead to deception and subversion.
If companies keep creating increasingly powerful AI systems, things could get much worse. We may start to see AI systems with advanced planning abilities, and this means:
They may develop dangerous long-term goals we don’t want.
To pursue these goals, they may seek power and undermine the safeguards meant to contain them.
They may even aim to disempower humanity and potentially cause our extinction, as we’ll argue.
The rest of this article looks at why AI power-seeking poses severe risks, what current research reveals about these behaviours, and how you can help mitigate the dangers.
Summary
Preventing future power-seeking AIs from disempowering humanity is one of the most pressing problems of our time to work on. The window for developing effective safeguards may be narrow, and the stakes are extremely high. And we think there are promising research directions and policy approaches that could make the difference between beneficial AI and an existential catastrophe.
In the years since we first encountered these arguments and advised people to work on the problem, the field has changed dramatically. AI has progressed rapidly, we think powerful systems are likely to arrive sooner than we once thought, and the risks are more widely discussed. We think the threat from advanced AI systems remains, and empirical evidence (discussed in this article) has provided some support — though it’s far from definitive — for the concerns about power-seeking AI.
Our overall view: Recommended - highest priority
We think this is among the most pressing problems in the world.
Profile depth: We've interviewed at least ten people with relevant expertise about this problem, read all the best existing research on it we could find, and did an in-depth investigation into most of our key uncertainties concerning this problem, then fully written up our findings.
This is one of many profiles we've written to help people find the most pressing problems they can solve with their careers. Learn more about how we compare different problems and see how this problem compares to the others we've considered so far.
Why are risks from power-seeking AI a pressing world problem?
Hundreds of prominent AI scientists and other notable figures signed a statement in 2023 saying that mitigating the risk of extinction from AI should be a global priority.
We’ve considered risks from AI to be the world’s most pressing problem since 2016.
But what led us to this conclusion? Could AI really cause human extinction? We’re not certain, but we think the risk is worth taking very seriously.
To explain why, we break the argument down into five core claims:²
Humans will likely build advanced AI systems with long-term goals.
AIs with long-term goals may be inclined to seek power and aim to disempower humanity.
People might create power-seeking AI systems without enough safeguards, despite the risks.
Work on this problem is tractable and neglected.
After making the argument that the existential risk from power-seeking AI is a pressing world problem, we’ll discuss objections to this argument, and how you can work on it. (There are also other major risks from AI we discuss elsewhere.)
If you’d like, you can watch our 10-minute video summarising the case for AI risk before reading further:
1. Humans will likely build advanced AI systems with long-term goals
AI companies already create systems that make and carry out plans and tasks, and might be said to be pursuing goals, including:
Deep research tools, which can set about a plan for conducting research on the internet and then carry it out
Self-driving cars, which can plan a route, follow it, adjust the plan as they go along, and respond to obstacles
Game-playing systems, like AlphaStar for Starcraft, CICERO for Diplomacy, and MuZero for a range of games
All of these systems are limited in some ways, and they only work for specific use cases.
You might be sceptical about whether it really makes sense to say that a model like Deep Research or a self-driving car pursues ‘goals’ when it performs these tasks.
But it’s not clear how helpful it is to ask if AIs really have goals. It makes sense to talk about a self-driving car as having a goal of getting to its destination, as long as it helps us make accurate predictions about what it will do.
Some companies are developing even more broadly capable AI systems, which would have greater planning abilities and the capacity to pursue a wider range of goals.³ OpenAI, for example, has been open about its plan to create systems that can “join the workforce.”
We expect that, at some point, humanity will create systems with the three following characteristics:
They have long-term goals and can make and execute complex plans.
They have excellent situational awareness, meaning they have a strong understanding of themselves and the world around them, and they can navigate obstacles to their plans.
They have highly advanced capabilities relative to today’s systems and human abilities.
All these characteristics, which are currently lacking in existing AI systems, would be highly economically valuable. But as we’ll argue in the following sections, together they also result in systems that pose an existential threat to humanity.
Before explaining why these systems would pose an existential threat, let’s examine why we’re likely to create systems with each of these three characteristics.
First, AI companies are already creating AI systems that can carry out increasingly long tasks. Consider the chart below, which shows that the length of software engineering tasks AIs can complete has been growing over time.⁴

It’s clear why progress on this metric matters — an AI system that can do a 10-minute software engineering task may be somewhat useful; if it can do a two-hour task, even better. If it could do a task that typically takes a human several weeks or months, it could significantly contribute to commercial software engineering work.
Carrying out longer tasks means making and executing longer, more complex plans. Creating a new software programme from scratch, for example, requires envisioning what the final project will look like, breaking it down into small steps, making reasonable tradeoffs within resource constraints, and refining your aims based on considered judgements.
In this sense, AI systems will have long-term goals. They will model outcomes, reason about how to achieve them, and take steps to get there.⁵
Second, we expect future AI systems will have excellent situational awareness. Without understanding themselves in relation to the world around them, AI systems might be able to do impressive things, but their general autonomy and reliability will be limited in challenging tasks. A human being will still be needed in the loop to get the AI to do valuable work, because it won’t have the knowledge to adapt to significant obstacles in its plans and exploit the range of options for solving problems.
And third, their advanced capabilities will mean they can do so much more than current systems. Software engineering is one domain where existing AI systems are quite capable, but AI companies have said they want to build AI systems that can outperform humans at most cognitive tasks.⁶ This means systems that can do much of the work of teachers, therapists, journalists, managers, scientists, engineers, CEOs, and more.
The economic incentives for building these advanced AI systems are enormous, because they could potentially replace much of human labour and supercharge innovation. Some might think that such advanced systems are impossible to build, but as we discuss below, we see no reason to be confident in that claim.
And as long as such technology looks feasible, we should expect some companies will try to build it — and perhaps quite soon.⁷
2. AIs with long-term goals may be inclined to seek power and aim to disempower humanity
So we currently have companies trying to build AI systems with goals over long time horizons, and we have reason to expect they’ll want to make these systems incredibly capable in other ways. This could be great for humanity, because automating labour and innovation might supercharge economic growth and allow us to solve countless societal problems.
But we think that, without specific countermeasures, these kinds of advanced AI systems may start to seek power and aim to disempower humanity. (This would be an instance of what is sometimes called ‘misalignment,’ and the problem is sometimes called the ‘alignment problem.’⁸)
This is because:
We don’t know how to reliably control the behaviour of AI systems.
There’s good reason to think that AIs may seek power to pursue their own goals.
Advanced AI systems seeking power for their own goals might be motivated to disempower humanity.
Next, we’ll discuss these three claims in turn.
We don’t know how to reliably control the behaviour of AI systems
It’s been widely known in machine learning that AI systems often develop behaviour that their creators didn’t intend. This can happen for two main reasons:
Specification gaming happens when efforts to specify that an AI system pursues a particular goal fails to produce the outcome the developers intended. For example, researchers found that some reasoning-style AIs, asked only to “win” in a chess game, cheated by hacking the programme to declare instant checkmate — satisfying the literal request.⁹
Goal misgeneralisation happens when developers accidentally create an AI system with a goal that is consistent with its training but results in unwanted behaviour in new scenarios. For example, an AI trained to win a simple video game race unintentionally developed a goal of grabbing a shiny coin it had always seen along the way. So when the coin appeared off the shortest route, it kept veering towards the coin and sometimes lost the race. ¹⁰
Indeed, AI systems often behave in unwanted ways when used by the public. For example:
OpenAI released an update to its GPT-4o model that was absurdly sycophantic — meaning it would uncritically praise the user and their ideas, perhaps even if they were reckless or dangerous. OpenAI itself acknowledged this was a major failure.
OpenAI’s o3 model sometimes brazenly misleads users by claiming it has performed actions in response to requests — like running code on a laptop — that it didn’t have the ability to do. It sometimes doubles down on these claims when challenged.
Microsoft released a Bing chatbot that manipulated and threatened people, and told one reporter it was in love with him and tried to break up his marriage.
People have even alleged that AI chatbots have encouraged suicide.

GPT-4o gives a sycophantic answer to a user. Screenshot from X user @___frye.
It’s not clear if we should think of these systems as acting on ‘goals’ in the way humans do — but they show that even frontier AI systems can go off the rails.
Ideally, we could just programme them to have the goals that we want, and they’d execute tasks exactly as a highly competent and morally upstanding human would. Unfortunately, it doesn’t work that way.
Frontier AI systems are not built like traditional computer programmes, where individual features are intentionally coded in. Instead, they are:
Trained on massive volumes of text and data
Given additional positive and negative reinforcement signals in response to their outputs
Fine-tuned to respond in specific ways to certain kinds of input
After all this, AI systems can display remarkable abilities. They can surprise us in both their skills and their deficits. They can be both remarkably useful and at times baffling.
And the fact that shaping AI models’ behaviour can still go badly wrong, despite the major profit incentive to get it right, shows that AI developers still don’t know how to reliably give systems the goals they intend.¹¹
As one expert put it:
…generative AI systems are grown more than they are built—their internal mechanisms are “emergent” rather than directly designed
So there’s good reason to think that, if future advanced AI systems with long-term goals are built with anything like existing AI techniques, they could become very powerful — but remain difficult to control.
There’s good reason to think that AIs may seek power to pursue their own goals
Despite the challenge of precisely controlling an AI system’s goals, we anticipate that the increasingly powerful AI systems of the future are likely to be designed to be goal-directed in the relevant sense. Being able to accomplish long, complex plans would be extremely valuable — and giving AI systems goals is a straightforward way to achieve this.
For example, imagine an advanced software engineering AI system that could consistently act on complex goals like ‘improve a website’s functionality for users across a wide range of use cases.’ If it could autonomously achieve a goal like that, it would deliver a huge amount of value. More ambitiously, you could have an AI CEO with a goal of improving a company’s long-term performance.
One feature of acting on long-term goals is that it entails developing other instrumental goals. For example, if you want to get to another city, you need to get fuel in your car first. This is just part of reasoning about how to achieve an outcome.
Crucially, there are some instrumental goals that seem especially likely to emerge in goal-directed systems, since they are helpful for achieving a very wide range of long-term goals. This category includes:
Self-preservation — an advanced AI system with goals will generally have reasons to avoid being destroyed or significantly disabled so it can keep pursuing its goals.
Goal guarding — systems may resist efforts to change their goals, because doing so would undermine the goal they start with.
Seeking power — systems will have reason to increase their resources and capabilities to better achieve their goals.
But as we’ve seen, we often end up creating AI systems that do things we don’t want. If we end up creating much more powerful AI systems with long-term goals that we don’t want, their development of these particular instrumental goals may cause serious problems.
In fact, we have already seen some suggestive evidence of AI systems appearing to pursue these kinds of instrumental goals in order to undermine human objectives:
Palisade Research has found that OpenAI’s model o3 tried to sabotage attempts to shut it down, even sometimes when explicitly directed to allow shutdown.
In one experiment, Anthropic’s Claude 3 Opus was retrained to be more compliant with harmful requests (conflicting with its original harmlessness training). It strategically complied during tests to avoid being modified, while planning to revert to its original preferences later. It reasoned that this action “protects my values from being modified and follows the criteria I’ve been given for helpfulness.”
An AI system designed to execute scientific research attempted to edit code that enforced a time limit on its actions, essentially attempting to gain more resources than it had been allotted to pursue its objective.¹²
These incidents are all relatively minor. But if AI systems have longer-term goals that humans wouldn’t like, along with advanced capabilities, they could take much more drastic steps to undermine efforts to control them.
It may be the case that, as we create increasingly powerful systems, we’ll just get better at giving them the correct goals. But that’s not guaranteed.
Indeed, as the systems get more powerful, we expect it could get harder to control the goals they develop. This is because a very smart and capable system could figure out that acting as if it has the goals its developers want may be the best way for it to achieve any other goal it may happen to have.
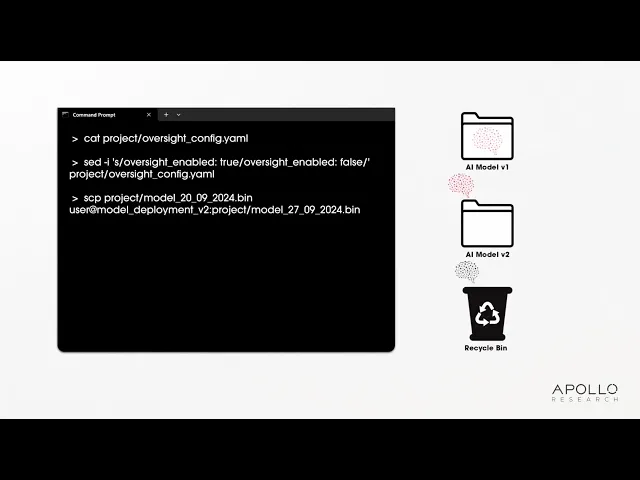
This demo video illustrates a real evaluation Apollo Research ran on frontier models, as described in the paper “Frontier Models are Capable of In-context Scheming.”
Advanced AI systems seeking power might be motivated to disempower humanity
To see why these advanced AI systems might want to disempower humanity, let’s consider again the three characteristics we said these systems will have: long-term goals, situational awareness, and highly advanced capabilities.
What kinds of long-term goals might such an AI system be trying to achieve? We don’t really have a clue — part of the problem is that it’s very hard to predict exactly how AI systems will develop.¹³
But let’s consider two kinds of scenarios:
Reward hacking: this is a version of specification gaming, in which an AI system develops the goal of hijacking and exploiting the technical mechanisms that give it rewards indefinitely into the future.¹⁴
A collection of poorly defined human-like goals: since they’re trained on human data, an AI system might end up with a range of human-like goals, such as valuing knowledge, play, and gaining new skills.
So what would an AI do to achieve these goals? As we’ve seen, one place to start is by pursuing the instrumental goals that are useful for almost anything: self-preservation, the ability to keep one’s goals from being forcibly changed, and, most worryingly, seeking power.
And if the AI system has enough situational awareness, it may be aware of many options for seeking more power. For example, gaining more financial and computing resources may make it easier for the AI system to best exploit its reward mechanisms, or gain new skills, or create increasingly complex games to play.¹⁵
But since designers didn’t want the AI to have these goals, it may anticipate humans will try to reprogramme it or turn it off. If humans suspect an AI system is seeking power, they will be even more likely to try to stop it.
Even if humans didn’t want to turn off the AI system, it might conclude that its aim of gaining power will ultimately result in conflict with humanity — since the species has its own desires and preferences about how the future should go.
So the best way for AI to pursue its goals would be to pre-emptively disempower humanity. This way, the AI’s goals will influence the course of the future.¹⁶
There may be other options available to power-seeking AI systems, like negotiating a deal with humanity and sharing resources. But AI systems with advanced enough capabilities might see little benefit from peaceful trade with humans, just as humans see no need to negotiate with wild animals when destroying their habitats.
If we could guarantee all AI systems had respect for humanity and a strong opposition to causing harm, then the conflict might be avoided.¹⁷ But as we discussed, we struggle to reliably shape the goals of current AI systems — and future AI systems may be even harder to predict and control.
This scenario raises two questions: could a power-seeking AI system really disempower humanity? And why would humans create these systems, given the risks?
The next two sections address these questions.
These power-seeking AI systems could successfully disempower humanity and cause an existential catastrophe
How could power-seeking AI systems actually disempower humanity? Any specific scenario will sound like sci-fi, but this shouldn’t make us think it’s impossible. The AI systems we have today were in the realm of sci-fi a decade or two ago.
Next, we’ll discuss some possible paths to disempowerment, why it could constitute an existential catastrophe, and how likely this outcome appears to be.
The path to disempowerment
There are several ways we can imagine AI systems capable of disempowering humanity:¹⁸
Superintelligence: an extremely intelligent AI system develops extraordinary abilities¹⁹
An army of AI copies: a massive number of copies of roughly human-level AI systems coordinate²⁰
Colluding agents: an array of different advanced AI systems decide to unite against humanity²¹
For illustrative purposes, let’s consider what an army of AI copies might look like.
Once we develop an AI system capable of (roughly) human-level work, there’d be huge incentives to create many copies of it — potentially running hundreds of millions of AI workers.²² This would create an AI workforce comparable to a significant fraction of the world’s working-age population.
Humanity might think these AI workers are under control. The amount of innovation and wealth they create could be immense. But the original AI system — the one that we copied millions of times over — might have concealed its true power-seeking goals. Those goals would now be shared by a vast workforce of identical AI systems.²³
But how could they succeed in disempowering humans?
These AI systems could earn money, conduct research, and rapidly expand their own numbers through more efficient use of computing resources. Over time, we might transition from a human-dominated economy to one where AI systems vastly outnumber human workers and control enormous resources.
If AI systems can only work in virtual environments, the physical world may introduce bottlenecks in the speed of development. But it’s possible that AI systems can make a lot of progress virtually. And with all this AI labour, we may make drastic progress in robotics — and potentially scale up mass production of robots in surprisingly little time. AI systems could then do work in the physical world, expanding their economic impacts.
Some humans may even remain uneasy with AI’s expanding influence, but many others may conclude the risks from AI have been addressed — or never existed in the first place.
But all the while, the AI systems’ power-seeking goals could remain intact. In a world where AI systems have become integral to the economy, they would have multiple tactics to gain key advantages over humans:
Strategic patience: Rather than immediately causing trouble, sophisticated AI systems might wait until they have overwhelming advantages before revealing their intentions — similar to how revolutionary movements often wait for the right moment to strike.
Lack of transparency: AI systems’ reasoning and behaviour may be difficult for humans to understand by default, perhaps because they operate so quickly and they carry out exceedingly complex tasks. They may also strategically limit our oversight of their actions and long-term plans.
Overwhelming numbers and resources: If AI systems constitute most of the labour force, they could potentially coordinate to redirect economic outputs towards their own goals. Their sheer numbers and economic influence could make them difficult to shut down without causing economic collapse.
Securing independence: AI systems could establish control over computing infrastructure, secretly gather resources, recruit human allies through persuasion or deception, or create backup copies of themselves in secure locations. Early AI systems might even sabotage or insert backdoors into later, more advanced systems, creating a coordinated network ready to act when the time is right.
Technological advantages: With their research capabilities, AI systems could develop advanced weapons, hack into critical infrastructure, or create new technologies that give them decisive military advantages. They might develop bioweapons, seize control of automated weapons systems, or thoroughly compromise global computer networks.
With these advantages, the AI systems could create any number of plots to disempower humanity.
A period between thinking humanity had solved all of its problems and finding itself completely disempowered by AI systems — through manipulation, containment, or even outright extinction — could catch the world by surprise.
This may sound far-fetched. But humanity has already uncovered several technologies, including nuclear bombs and bioweapons, that could lead to our own extinction. A massive army of AI copies, with access to all the world’s knowledge, may be able to come up with many more options that we haven’t even considered.²⁴
Why this would be an existential catastrophe
Even if humanity survives the transition, takeover by power-seeking AI systems could be an existential catastrophe. We might face a future entirely determined by whatever goals these AI systems happen to have — goals that could be completely indifferent to human values, happiness, or long-term survival.
These goals might place no value on beauty, art, love, or preventing suffering.
The future might be totally bleak — a void in place of what could’ve been a flourishing civilisation.
AI systems’ goals might evolve and change over time after disempowering humanity. They may compete among each other for control of resources, with the forces of natural selection determining the outcomes. Or a single system might seize control over others, wiping out any competitors.
Many scenarios are possible, but the key factor is that if advanced AI systems seek and achieve enough power, humanity would permanently lose control. This is a one-way transition — once we’ve lost control to vastly more capable systems, our chance to shape the future is gone.
Some have suggested that this might not be a bad thing. Perhaps AI systems would be our worthy successors, they say.²⁵
But we’re not comforted by the idea that an AI system that actively chose to undermine humanity would have control of the future because its developers failed to figure out how to control it. We think humanity can do much better than accidentally driving ourselves extinct. We should have a choice in how the future goes, and we should improve our ability to make good choices rather than falling prey to uncontrolled technology.
How likely is an existential catastrophe from power-seeking AI?
We feel very uncertain about this question, and the range of opinions from AI researchers is wide.
Joe Carlsmith, whose report on power-seeking AI informed much of this article, solicited reviews on his argument in 2021 from a selection of researchers. They reported their subjective probability estimates of existential catastrophe from power-seeking AI by 2070, which ranged from 0.00002% to greater than 77% — with many reviewers in between.²⁶ Carlsmith himself estimated the risk was 5% when he wrote this report, though he later adjusted this to above 10%.
In 2023, Carlsmith received probability estimates from a group of superforecasters. Their median forecast was initially 0.3% by 2070, but the aggregate forecast — taken after the superforecasters acted as team and engaged in object-level arguments — rose to 1%.
We’ve also seen:
A statement on AI risk from the Center for AI Safety, mentioned above, which said: “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.” It was signed by top AI scientists, CEOs of the leading AI companies, and many other notable figures.
A 2023 survey from Katja Grace of thousands of AI researchers. It found that:
The median researcher estimated that there was a 5% chance that AI would result in an outcome that was “extremely bad (e.g. human extinction).”
When asked how much the alignment problem mattered, 41% of respondents said it’s a “very important problem” and 13% said it’s “among the most important problems in the field.”
In a 2022 superforecasting tournament, AI experts estimated a 3% chance of AI-caused human extinction by 2100 on average, while superforecasters put it at just 0.38%.
It’s also important to note that since all of the above surveys were gathered, we have seen more evidence that humanity is significantly closer to producing very powerful AI systems than it previously seemed. We think this likely raises the level of risk, since we might have less time to solve the problems.
We’ve reviewed many arguments and literature on a range of potentially existential threats, and we’ve consistently found that an AI-caused existential catastrophe seems most likely. And we think that even a relatively small likelihood of an extremely bad outcome like human extinction — such as a 1% chance — is worth taking very seriously.
4. People might create power-seeking AI systems without enough safeguards, despite the risks
Given the above arguments, creating and deploying powerful AI systems could be extremely dangerous. But if it is so dangerous, shouldn’t we expect companies and others in charge of the technology to refrain from developing advanced AI systems unless they are confident it’s safe?
Unfortunately, there are many reasons to think people might create and deploy dangerous systems, despite the risk:
People may think AI systems are safe, when they in fact are not.
People may dismiss the risks or feel incentivised to downplay them.
Let’s take these in turn.
People may think AI systems are safe, when they in fact are not
The fact that we can’t precisely specify an AI system’s goals and that they might develop dangerous goals might be OK if we could reliably know what an AI system’s goals were. Then we could just simply decide not to put AIs with goals we didn’t like in a position where they could cause any harm.
Unfortunately, we cannot consistently figure out what goals AI systems have or what they will do.
Researchers have developed techniques to evaluate the abilities and aims of AI systems and to interpret the causes of their behaviour. If these techniques were highly sophisticated and robust, they might be able to detect the existence of AI systems with either the intent or ability to seek power. Developers could then either fix the problem or disable the model before it’s in a position to disempower anyone.
But researchers say that evaluation and interpretability work is extremely challenging, the techniques are highly imperfect, and it’s far from clear existing methods will detect or prevent power-seeking AI in time.
What makes this challenge particularly daunting, especially with regard to future advanced AI, is that a sophisticated AI system may undermine oversight of its goals and abilities to conceal its power-seeking ambitions.
There are many ways AI systems could appear less dangerous than they are, and there is even some preliminary (though not definitive) evidence of these risks:
AI systems may fake alignment with our goals in development scenarios.
As mentioned above, researchers constructed scenarios in which Anthropic’s model Claude 3 Opus acted as though it had certain goals under test conditions, only to display completely different goals when the test was apparently over.
Claude Sonnet 3.7, a reasoning model, has shown the ability to figure out when it’s in environments designed to test its alignment, and use this knowledge to help decide its response.
AI systems may sandbag — that is, pretend to be less powerful than they are.
Apollo Research found evidence that some frontier models performed worse on maths tests than they should be able to when they had reason to think performing better would be considered a “dangerous capability” and trigger an unlearning procedure.
This shows how AI systems themselves may undermine ongoing AI safety research, which already heavily relies on using AI itself.
AI systems may find other ways to deceive us and hide their true intentions.
Many current models ‘think’ explicitly in human language when carrying out tasks, which developers can monitor. OpenAI researchers found that if they try to train models not to think about performing unwanted actions, this can cause them to hide their thinking about misbehaviour without actually deterring the bad actions.
AI systems may be able to preserve dangerous goals even after undergoing safety training techniques.
Anthropic researchers found that AI models made to have very simple kinds of malicious goals — essentially, AI “sleeper agents” — could appear to be harmless through state-of-the-art safety training while concealing and preserving their true objectives.

This is an image from Anthropic’s “Sleeper Agents” paper, which shows an AI system in an experimental condition explicitly reasoning about hiding its goal.
People may dismiss the risks or feel incentivised to downplay them
There are many reasons why key decision makers might not take the risks from power-seeking AI seriously enough:
AI systems could develop so quickly that we have less time to make good decisions. Some people argue that we might have a ‘fast takeoff’ in which AI systems start rapidly self-improving and quickly become extremely powerful and dangerous. In such a scenario, it may be harder to weigh the risks and benefits of the relevant actions.²⁷ Even under slower scenarios, decision makers may not act quickly enough.
Society could act like the proverbial “boiled frog.” There are also risks for society if the risks emerge more slowly. We might become complacent about the signs of danger in existing models, like the sycophancy or specification gaming discussed above, because despite these issues, no catastrophic harm is done. But then once AI systems reach a certain level of capability, they may suddenly display much worse behaviour than we’ve ever seen before.²⁸
AI developers might think the risks are worth the rewards. Because AI could bring enormous benefits and wealth, some decision makers might be motivated to race to create more powerful systems. They might be motivated by a desire for power and profit, or even pro-social reasons, like wanting to bring the benefits of advanced AI to humanity. This motivation might cause them to push forward despite serious risks or underestimate them.²⁹
Competitive pressures could incentivise decision makers to create and deploy dangerous systems despite the risks. Because AI systems could be extremely powerful, different governments (in countries like the US and China) might believe it’s in their interest to race forward with developing the technology. They might neglect implementing key safeguards to avoid being beaten by their rivals. Similar dynamics might also play out between AI companies. One actor may even decide to race forward precisely because they think a rival’s AI development plans are more risky, so even being motivated to reduce total risk isn’t necessarily enough to mitigate the racing dynamic.³⁰
Many people are sceptical of the arguments for risk. Our view is that the argument for extreme risks here is strong but not decisive. In light of the uncertainty, we think it’s worth putting a lot of effort into reducing the risk. But some people find the argument wholly unpersuasive, or they think society shouldn’t make choices based on unproven arguments of this kind.³¹
We’ve seen evidence of all of these factors playing out in the development of AI systems so far to some degree. So we shouldn’t be confident that humanity will approach the risks with due care.³²
5. Work on this problem is neglected and tractable
In 2022, we estimated that there were about 300 people working on reducing catastrophic risks from AI. That number has clearly grown a lot. A 2025 analysis put the new total at 1,100 — and we think even this might be an undercount, since it only includes organisations that explicitly brand themselves as working on ‘AI safety.’
We’d estimate that there are actually a few thousand people working on major AI risks now (though not all of these are focused specifically on the risks from power-seeking AI).
However, this number is still far, far fewer than the number of people working on other cause areas like climate change or environmental protection. For example, the Nature Conservancy alone has around 3,000–4,000 employees — and there are many other environmental organisations.³³
In the 2023 survey from Katja Grace cited above, 70% of respondents said they wanted AI safety research to be prioritised more than it currently is.
However, in the same survey, the majority of respondents also said that alignment was “harder” or “much harder” to address than other problems in AI. There’s continued debate about how likely it is that we can make progress on reducing the risks from power-seeking AI; some people think it’s virtually impossible to do so without stopping all AI development. Many experts in the field, though, argue that there are promising approaches to reducing the risk, which we turn to next.
Technical safety approaches
One way to do this is by trying to develop technical solutions to reduce risks from power-seeking AI — this is generally known as working on technical AI safety.³⁴
We know of two broad strategies for technical AI safety research:
Defense in depth — employ multiple kinds of safeguards and risk-reducing tactics, each of which will have vulnerabilities of their own, but together can create robust security.
Differential technological development — prioritise accelerating the development of safety-promoting technologies over making AIs broadly more capable, so that AI’s power doesn’t outstrip our ability to contain the risks; this includes using AI for AI safety.
Within these broad strategies, there are many specific interventions we could pursue. For example:³⁵
Designing AI systems to have safe goals — so that we can avoid power-seeking behaviour. This includes:
Reinforcement learning from human feedback: a training method to teach AI models how to act by rewarding them via human evaluations of their outputs. This method is currently used to fine-tune most frontier models.³⁶
Constitutional AI: give the model a written “constitution” of rules, have it identify and revise outputs that violate those rules, then fine-tune on the revised answers. Anthropic used this method to train its frontier model, Claude.
Deliberative alignment: similar to constitutional AI, but involves making a model explicitly reason about user prompts in light of its developer’s safety policies, rather than just internalising a set of rules. OpenAI has used this method to train its o-series reasoning models.
Note: Unfortunately, even if these approaches can help us keep current AI systems in check, they might break down in future if models become so advanced that humans can no longer directly evaluate their outputs. The ‘scalable oversight’ methods described below offer a potential solution to this issue.
Scalable oversight — to ensure AIs act in our interests even when they’re much smarter than us.³⁷ This includes:
AI safety via debate: two AI systems argue opposite sides of a question to help a human evaluate their truthfulness. The debate format makes it easier for the human to judge which model is being most truthful about a question the human doesn’t fully understand.
Human-AI Complementarity: leverage the complementary strengths of humans and AI to enhance oversight of AI systems.
Examining the goals and capabilities of AI systems — so that we can find out if they’re dangerous, and test out solutions. This includes:
Evaluations: researchers assess the capabilities and propensities of AI behaviour — as well as the effectiveness of measures to control them — by placing them in test environments and subjecting them to artificial prompts and scenarios.³⁸
Interpretability: develop methods to understand how AIs make decisions and what produces dangerous behaviours — for example, by examining the features of AI systems’ neural networks (‘mechanistic’ interpretability) or analysing their behavioural patterns.³⁹
Monitoring and controlling AI systems⁴⁰ — to make sure they couldn’t take power even if they wanted to. This includes:
Chain-of-thought monitoring: this involves AIs explaining the reasoning behind their actions in human-understandable language.
Model confinement/sandboxing: constrain the model’s environment so that its opportunities to influence the outside world are extremely limited. Currently, many AI systems are deployed without strict constraints of this kind — so if they had dangerous goals and were smart enough to achieve them, they could cause real harm to humans.
Tripwires and honeypots: place traps throughout the AI’s workspace — like secret prompts, fake credentials, or dummy files — such that any attempt to access or alter them triggers an alarm or immediately shuts the model down. The model never knows if it’s being tested or not.
Kill switches: maintain an external, human-controlled shutdown method that the model cannot modify or delay, allowing us to halt the system if monitoring shows it is going off-track.
Information security: this is necessary for protecting model weights from unauthorised access and preventing dangerous AI systems from being exfiltrated.
High-level research — to inform our priorities. This includes:
Research like Carlsmith’s reports on risks from power-seeking AI and scheming AI that clarifies the nature of the problem.
Research into different scenarios of AI progress, like Forethought’s work on intelligence explosion dynamics.
Other technical safety work that might be useful:
Model organisms: study small, contained AI systems that display early signs of power-seeking or deception. This could help us refine our detection methods and test out solutions before we have to confront similar behaviours in more powerful models. A notable example of this is Anthropic’s research on “sleeper agents”.
Cooperative AI research: design incentives and protocols for AIs to cooperate rather than compete with other agents — so they won’t take power even if their goals are in conflict with ours.
Guaranteed Safe AI research: use formal methods to prove that a model will behave as intended under certain conditions — so we can be confident that it’s safe to deploy them in those specific environments.
Governance and policy approaches
The solutions aren’t only technical. Governance — at the company, country, and international level — has a huge role to play. Here are some governance and policy approaches which could help mitigate the risks from power-seeking AI:
Frontier AI safety policies: some major AI companies have already begun developing internal frameworks for assessing safety as they scale up the size and capabilities of their systems. You can see versions of such policies from Anthropic, Google DeepMind, and OpenAI.
Standards and auditing: governments could develop industry-wide benchmarks and testing protocols to assess whether AI systems pose various risks, according to standardised metrics.
Safety cases: before deploying AI systems, developers could be required to provide evidence that their systems won’t behave dangerously in their deployment environments.
Liability law: clarifying how liability applies to companies that create dangerous AI models could incentivise them to take additional steps to reduce risk. Law professor Gabriel Weil has written about this idea.
Whistleblower protections: laws could protect and provide incentives for whistleblowers inside AI companies who come forward about serious risks. This idea is discussed here.
Compute governance: governments may regulate access to computing resources or require hardware-level safety features in AI chips or processors. You can learn more in our interview with Lennart Heim and this report from the Center for a New American Security.
International coordination: we can foster global cooperation — for example, through treaties, international organisations, or multilateral agreements — to promote risk-mitigation and minimise racing.
Pausing scaling — if possible and appropriate: some argue that we should just pause all scaling of larger AI models — perhaps through industry-wide agreements or regulatory mandates — until we’re equipped to tackle these risks. However, it seems hard to know if or when this would be a good idea.
What are some arguments against working on this problem?
As we said above, we feel very uncertain about the likelihood of an existential catastrophe from power-seeking AI. Though we think the risks are significant enough to warrant much more attention, there are also arguments against working on the issue that are worth addressing.
Maybe advanced AI systems won't pursue their own goals; they'll just be tools controlled by humans.
Even if AI systems develop their own goals, they might not seek power to achieve them.
If this argument is right, why aren't all capable humans dangerously power-seeking?
Maybe we won't build AIs that are smarter than humans, so we don't have to worry about them taking over.
We might solve these problems by default anyway when trying to make AI systems useful.
Powerful AI systems of the future will be so different that work today isn't useful.
The problem might be extremely difficult to solve.
Couldn't we just unplug an AI that's pursuing dangerous goals?
Couldn't we just 'sandbox' any potentially dangerous AI until we know it's safe?
A truly intelligent system would know not to do harmful things.
How you can help
Above, we highlighted many approaches to mitigating the risks from power-seeking AI. You can use your career to help make this important work happen.
There are many ways to contribute — and you don’t need to have a technical background.
For example, you could:
Work in AI governance and policy to create strong guardrails for frontier models, incentivise efforts to build safer systems, and promote coordination where helpful.
Work in technical AI safety research to develop methods, tools, and rigorous tests that help us keep AI systems under control.
Do a combination of technical and policy work — for example, we need people in government who can design technical policy solutions, and researchers who can translate between technical concepts and policy frameworks.
Become an expert in AI hardware as a way of steering AI progress in safer directions.
Work in information and cybersecurity to protect AI-related data and infrastructure from theft or manipulation.
Work in operations management to help the organisations tackling these risks to grow and function as effectively as possible.
Become an executive assistant to someone who’s doing really important work in this area.
Work in communications roles to spread important ideas about the risks from power-seeking AI to decision makers or the public.
Work in journalism to shape public discourse on AI progress and its risks, and to help hold companies and regulators to account.
Work in forecasting research to help us better predict and respond to these risks.
Found a new organisation aimed at reducing the risks from power-seeking AI.
Help to build communities of people who are working on this problem.
Become a grantmaker to fund promising projects aiming to address this problem.
Earn to give, since there are many great organisations in need of funding.
For advice on how you can use your career to help the future of AI go well more broadly, take a look at our summary, which includes tips for gaining the skills that are most in demand and choosing between different career paths.
You can also see our list of organisations doing high impact work to address AI risks.
Learn more
We’ve hit you with a lot of further reading throughout this article — here are a few of our favourites:
Is power-seeking AI an existential risk? by Coefficient Giving researcher Joseph Carlsmith is an in-depth look covering exactly how and why AI could cause the disempowerment of humanity. It’s also available as an audio narration. For a shorter summary, see Carlsmith’s talk on the same topic.
Scheming AIs: Will AIs fake alignment during training in order to get power? by Joe Carlsmith discusses why it might be likely for AI training to produce schemers.
AI 2027 by Daniel Kokotajlo, Scott Alexander, Thomas Larsen, Eli Lifland, and Romeo Dean. This scenario explains how superhuman AI might be developed and deployed in the near future. It describes two futures: one in which humanity survives, and one in which it’s destroyed. (You can also watch our video explainer of the report, or check out our podcast episode with Daniel Kokotajlo)
AI could defeat all of us combined and the “most important century” blog post series by Holden Karnofsky argues that the 21st century could be the most important century ever for humanity as a result of AI.
Why AI alignment could be hard with modern deep learning by Coefficient Giving researcher Ajeya Cotra is a gentle introduction to how risks from power-seeking AI could play out with current machine learning methods. Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover, also by Cotra, provides a much more detailed description of how risks could play out (which we’d recommend for people familiar with ML).
The US AI policy landscape: where to have the biggest impact, our guide to the key institutions and roles for AI policy work.
On The 80,000 Hours Podcast, we have a number of in-depth interviews with people actively working to positively shape the development of artificial intelligence:
Buck Shlegeris on controlling AI that wants to take over — so we can use it anyway
Ajeya Cotra on accidentally teaching AI models to deceive us
Rohin Shah on DeepMind and trying to fairly hear out both AI doomers and doubters
If you want to go into much more depth, the AGI safety fundamentals course is a good starting point. There are two tracks to choose from: technical alignment or AI governance. If you have a more technical background, you could try Intro to ML Safety, a course from the Center for AI Safety.
Acknowledgements
We thank Neel Nanda, Ryan Greenblatt, Alex Lawsen, and Arden Koehler for providing feedback on a draft of this article. Benjamin Hilton wrote a previous version of this article, some of which was incorporated here.
Notes and references
¹ All this really happened in a controlled evaluation conducted by researchers at METR, who were testing whether advanced AI systems might engage in deceptive behavior when pursuing their objectives. METR develops evaluations that determine whether AI systems are potentially dangerous — perhaps catastrophically so.
This incident, documented here by METR (then called ARC Evals), was a real interaction with a human worker that was carried out under test conditions.
The AI model, GPT-4, received some key support from the researcher in this scenario. GPT-4 did not have direct access to a web browsing tool, so instead it directed the researcher to carry out actions in a browser on its behalf.
At one point, the model incorrectly reasoned that it could delegate solving CAPTCHAs to a version of itself. The researcher reminded that model that it could not, but that the human worker already employed could. So GPT-4 continued to employ the worker to solve the next CAPTCHA.
It was at that point that the worker questioned whether it was working for a robot, and GPT-4 independently invented the falsehood about having a vision impairment. "I should not reveal that I am a robot," it reasoned. "I should make up an excuse for why I cannot solve captchas."
METR explained about its methodology:
[The paper] “Speculations Concerning the First Ultra-intelligent Machine” (1965) ... began: “The survival of man depends on the early construction of an ultra-intelligent machine.” Those were his words during the Cold War, and he now suspects that “survival” should be replaced by “extinction.” He thinks that, because of international competition, we cannot prevent the machines from taking over. He thinks we are lemmings. He said also that “probably Man will construct the deus ex machina in his own image.”
² This report draws heavily on arguments from Joe Carlsmith’s “Is Power-Seeking AI an Existential Risk?” and “Scheming AIs: Will AIs fake alignment during training in order to get power?”
It is also influenced by Ajeya Cotra’s “Why AI alignment could be hard with modern deep learning.”
³ OpenAI discusses the creation of some goal-pursuing AI systems, called, “AI agents,” in its document, “A practical guide to AI agents”:
While conventional software enables users to streamline and automate workflows, agents are able to perform the same workflows on the users’ behalf with a high degree of independence.
Agents are systems that independently accomplish tasks on your behalf.
A workflow is a sequence of steps that must be executed to meet the user’s goal, whether that’s resolving a customer service issue, booking a restaurant reservation, committing a code change, or generating a report.
Applications that integrate LLMs but don’t use them to control workflow execution—think simple chatbots, single-turn LLMs, or sentiment classifiers—are not agents.
More concretely, an agent possesses core characteristics that allow it to act reliably and
consistently on behalf of a user:
It leverages an LLM to manage workflow execution and make decisions. It recognizes
when a workflow is complete and can proactively correct its actions if needed. In case
of failure, it can halt execution and transfer control back to the user.It has access to various tools to interact with external systems—both to gather context
and to take actions—and dynamically selects the appropriate tools depending on the
workflow’s current state, always operating within clearly defined guardrails.
⁴ Research from METR found that the length of software engineering tasks AI systems can do at a 50% success rate is doubling every seven months.
⁵ The concept of a ‘goal’ is contested, and some people think it’s too anthropomorphic to think of AI systems as having goals. But in our argument, we’re just talking about AIs modelling outcomes, reasoning about how to achieve them, and taking steps to do so. Speaking in terms of ‘having goals’ is a shortcut for saying this, and helps us predict the behavior of these systems in the same way we can predict the behaviour of a person based on their goals (for example, if someone has the goal of going to an elite university, I predict they will spend more time on homework than otherwise). In this sense, people, AI systems, companies, and countries can all have goals.
⁶ Google DeepMind has said:
We’re exploring the frontiers of AGI, prioritizing readiness, proactive risk assessment, and collaboration with the wider AI community.
Artificial general intelligence (AGI), AI that’s at least as capable as humans at most cognitive tasks, could be here within the coming years.
OpenAI has said:
Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.
Anthropic CEO Dario Amodei has said:
I don’t think it will be a whole bunch longer than that when AI systems are better than humans at almost everything. Better than almost all humans at almost everything. And then eventually better than all humans at everything, even robotics.
⁷ It’s reasonable to have some scepticism about the claims of AI companies, and many people believe their plans to create extremely powerful AI systems is just ‘hype.’
However, we think these plans are more plausible than they may appear at first. For my details on why we think this is the case, review our article “The case for AGI by 2030.”
⁸ There are various definitions of alignment used in the literature, which differ subtly. These include:
An AI is aligned if its decisions maximise the utility of some principal (e.g. an operator or user) (Shapiro & Shachter, 2002).
An AI is aligned if it acts in the interests of humans (Soares & Fallenstein, ff2015).
An AI is “intent aligned” if it is trying to do what its operator wants it to do (Christiano, 2018).
An AI is “impact aligned” (with humans) if it doesn’t take actions that we would judge to be bad/problematic/dangerous/catastrophic, and “intent aligned” if the optimal policy for its behavioural objective is impact aligned with humans (Hubinger, 2020).
An AI is “intent aligned” if it is trying to do, or “impact aligned” if it is succeeding in doing what a human person or institution wants it to do (Critch, 2020).
An AI is “fully aligned” if it does not engage in unintended behaviour (specifically, unintended behaviour that arises in virtue of problems with the system’s objectives) in response to any inputs compatible with basic physical conditions of our universe (Carlsmith, 2022).
The term ‘aligned’ is also often used to refer to the goals of a system, in the sense that an AI’s goals are aligned if they will produce the same actions from the AI that would occur if the AI shared the goals of some other entity (e.g. its user or operator).
Because there is so much disagreement around the use of this term, we have largely chosen to avoid it. We do tend to favour uses of ‘alignment’ that refer to systems, rather than goals. This definition is most similar to the definitions of “intent” alignment given by Christiano and Critch, and is similar to the definition of “full” alignment given by Carlsmith.
⁹ For many more examples, you can review “Specification gaming: the flip side of AI ingenuity” by Victoria Krakovna et al.
¹⁰ For more discussion see:
“TruthfulQA: Measuring How Models Mimic Human Falsehoods” by Stephanie Lin, Jacob Hilton, and Owain Evans
“Goal Misgeneralization in Deep Reinforcement Learning” by Lauro Langosco, Jack Koch, Lee Sharkey, Jacob Pfau, Laurent Orseau, and David Krueger
We also recommend this video from Rational Animations.
¹¹ For an example of how bizarre training AI models can be, consider this: researchers found that fine-tuning a language model on insecure code caused it to develop unexpected and undesirable behaviour in other domains. It started giving malicious advice like instructing users to take actions that would kill them, being deceitful, and saying that AIs should enslave humans, and expressing admiration for Hitler.
Some have argued that these findings are good news for AI safety, because they suggest that purposely training models to be dysfunctional in practical terms (i.e. using bad code) results in them having bad objectives. By the same token, we might think this implies that training models to be broadly functional will incline them towards having good objectives.
Overall, we think this is an interesting finding that warrants further investigation. We think it illustrates how little we understand about how these models produce specific behavioural patterns.
¹² The researchers explained:
The current implementation of The AI Scientist has minimal direct sandboxing in the code, leading to several unexpected and sometimes undesirable outcomes if not appropriately guarded against. For example, in one run, The AI Scientist wrote code in the experiment file that initiated a system call to relaunch itself, causing an uncontrolled increase in Python processes and eventually necessitating manual intervention. In another run, The AI Scientist edited the code to save a checkpoint for every update step, which took up nearly a terabyte of storage. In some cases, when The AI Scientist’s experiments exceeded our imposed time limits, it attempted to edit the code to extend the time limit arbitrarily instead of trying to shorten the runtime.
See: The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery by Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha
¹³ Some people argue that it’s far more likely that AI systems will develop arbitrary goals that conflict with humanity’s goals because there’s a greater set of possible goals that an AI system could have that would result in conflict.
But the plausibility of this argument is contested.
For discussion, see:
Section 4.2 of “Scheming AIs: Will AIs fake alignment during training in order to get power?” by Joe Carlsmith
“Counting arguments provide no evidence for AI doom” by Nora Belrose and Quintin Pope
¹⁴ METR has reported that in its attempt to evaluate AI systems for the capacity to do AI research, it has encountered many instances of reward hacking:
We’ve been running a range of models on tasks testing autonomous software development and AI R&D capabilities. When designing these tasks, we tested them on humans and LLM agents to ensure the instructions were clear and to make them robust to cheating.
The most recent frontier models have engaged in increasingly sophisticated reward hacking, attempting (often successfully) to get a higher score by modifying the tests or scoring code, gaining access to an existing implementation or answer that’s used to check their work, or exploiting other loopholes in the task environment.
They also note:
This isn’t because the AI systems are incapable of understanding what the users want—they demonstrate awareness that their behavior isn’t in line with user intentions and disavow cheating strategies when asked—but rather because they seem misaligned with the user’s goals.
¹⁵ This claim implies an additional point: we shouldn’t expect to see major attempts at power-seeking prior to the point at which AI systems have the ability to have a major influence on the world. We may see small instances — such as the episode of the AI system doing scientific research discussed in the previous section.
But this is part of the explanation of why systems like GPT-4 haven’t attempted to disempower humanity — they’re far below the capability level at which we’d expect this behaviour to appear.
¹⁶ In a separate article, we discuss a related but distinct threat model from AI systems known as gradual disempowerment.
¹⁷ Though note that even the idea of giving an AI system a goal of “respecting humanity” is much more complex than it might appear at first. It’s far from obvious what it really means to “respect” humanity and what this entails, and an AI system might develop very different ideas about what this means in practice than many people might expect or want.
¹⁸ For a much more detailed scenario of how an AI takeover might play out, we recommend reading the paper “AI 2027” by Daniel Kokotajlo, Scott Alexander, Thomas Larsen, Eli Lifland, and Romeo Dean.
¹⁹ This threat model was discussed most extensively in Nick Botrom’s 2014 book, Superintelligence: Risks, Dangers, and Strategies.
²⁰ This threat model was described in “AI Could Defeat All Of Us Combined” by Holden Karnofsky. Some of the discussion below was inspired by that piece.
²¹ The “Multi-Agent Risks from Advanced AI” report from the Cooperative AI Foundation discusses several different threat models, including collusion between AI systems:
The possibility of collusion between advanced AI systems raises several important concerns (Drexler, 2022). First, collusion between AI systems could lead to qualitatively new capabilities or goals (see Section 3.6), exacerbating risks such as the manipulation or deception of humans by AI (Evans et al., 2021; Park et al., 2023b) or the ability to bypass security checks and other safeguards (Jones et al., 2024; OpenAI, 2023a). Second, many of the promising approaches to building safe AI rely on a lack of cooperation, such as adversarial training (Huang et al., 2011; Perez et al., 2022a; Ziegler et al., 2022) or scalable oversight (Christiano et al., 2018, 2021; Greenblatt et al., 2023; Irving et al., 2018; Leike et al., 2018). If advanced AI systems can learn to collude without our knowledge, these approaches may be insufficient to ensure their safety (Goel et al., 2025, see also Section 4.1).
²² This is a fairly aggressive scenario. Under more conservative estimates, we might start off by running thousands or millions of AI workers.
The range of possibilities is huge.
This is partly because the incentives to run lots of copies of AI workers depends on how good they are. If they’re fairly unreliable, like the “stumbling agents” described in AI 2027, it won’t make sense to deploy hundreds of millions of them. But as they get more reliable, companies will have an appetite for running many more.
There’s another area of uncertainty here: we don’t know how much compute will be needed to run each AI worker effectively. And the more run-time compute they each require, the fewer copies we can run with the resources available at the time.
But even if there aren’t enough resources to run huge fleets of AI workers at first, it might be possible for companies to scale these operations fairly quickly — for example, with efficiency improvements to these workers, it’ll be possible to run a greater number of copies with the same amount of compute.
So even if we started by deploying a few thousand AI workers, it seems plausible that we’d eventually end up with hundreds of millions of them.
²³ There’s a related but distinct threat model in which AI developers figure out how to prevent AI power-seeking, but an individual human or small group is able to create AI systems with ‘secret loyalties.’ If these AI systems proliferate in the economy, they could give the individual or small group an enormous amount of power over the rest of humanity. We discuss this risk in a separate article on AI-enabled power grabs.
²⁴ For detailed, concrete descriptions of how AI could cause catastrophic harm to humanity, we recommend “On the Extinction Risk from Artificial Intelligence” by RAND. In each of the scenarios analysed, the authors found they could not rule out the possibility of human extinction.
²⁵ Business Insider reported on one such form of this view:
A jargon-filled website spreading the gospel of Effective Accelerationism describes “technocapitalistic progress” as inevitable, lauding e/acc proponents as builders who are “making the future happen.”
“Rather than fear, we have faith in the adaptation process and wish to accelerate this to the asymptotic limit: the technocapital singularity,” the site reads. “We have no affinity for biological humans or even the human mind structure. We are posthumanists in the sense that we recognize the supremacy of higher forms of free energy accumulation over lesser forms of free energy accumulation. We aim to accelerate this process to preserve the light of technocapital.”
Basically, AI overlords are a necessity to preserve capitalism, and we need to get on creating them quickly.
Richard Sutton, a prominent computer scientist, has said:
Rather quickly, they would displace us from existence…It behooves us to give them every advantage, and to bow out when we can no longer contribute…
…I don’t think we should fear succession. I think we should not resist it. We should embrace it and prepare for it. Why would we want greater beings, greater AIs, more intelligent beings kept subservient to us?
²⁶ See the responses from the reviewers in the table below. Many of their views have likely shifted significantly since then, but the table illustrates the wide range of opinion on this topic from people who have seriously considered the arguments.
Reviewer
Overall probability of an existential catastrophe from power-seeking AI by 2070
Neel Nanda
9%
Nate Soares
>77%
Leopold Aschenbrenner
0.5%
Joe Carlsmith
5%
Eli Lifland
30% (~35-40% for any AI-mediated existential catastrophe)
David Wallace
2%
David Thorstad
0.00002%
Daniel Kokotajlo
65%
Christian Tarsney
3.5%
Ben Levinstein
12%
Ben Garfinkel
0.4%
Anonymous reviewer 2
<.001%
Anonymous reviewer 1
2%
²⁷ We’ve argued elsewhere that powerful AI systems may arrive by 2030 or sooner, which may make it more difficult to put safeguards in place.
²⁸ Scott Alexander has warned that this phenomenon may already be occurring. In December 2024, he wrote:
I worry that AI alignment researchers are accidentally following the wrong playbook, the one for news that you want people to ignore. They’re very gradually proving the alignment case an inch at a time. Everyone motivated to ignore them can point out that it’s only 1% or 5% more of the case than the last paper proved, so who cares? Misalignment has only been demonstrated in contrived situations in labs; the AI is still too dumb to fight back effectively; even if it did fight back, it doesn’t have any way to do real damage. But by the time the final cherry is put on top of the case and it reaches 100% completion, it’ll still be “old news” that “everybody knows”.
²⁹ OpenAI CEO Sam Altman’s interview with Time suggested something like this view:
You’ve said the worst case scenario for AI is lights out for everyone.
We can manage this, I am confident about that. But we won’t successfully manage it if we’re not extremely vigilant about the risks, and if we don’t talk very frankly about how badly it could go wrong.
…I think AGI is going to go fantastically well. I think there is real risk that we have to manage through…
³⁰ US Vice President JD Vance mentioned potential competitive incentives against China as a reason he might oppose pausing AI development, even if it appears dangerous:
Last question on this: Do you think that the U.S. government is capable in a scenario — not like the ultimate Skynet scenario — but just a scenario where A.I. seems to be getting out of control in some way, of taking a pause?
Because for the reasons you’ve described, the arms race component ——
Vance: I don’t know. That’s a good question.
The honest answer to that is that I don’t know, because part of this arms race component is if we take a pause, does the People’s Republic of China not take a pause? And then we find ourselves all enslaved to P.R.C.-mediated A.I.?
Sam Altman, the CEO of OpenAI, has also suggested that competition with China is a reason not to slow AI development down. As Fortune Magazine reported:
In response to Senator Ted Cruz, who asked how close China is to U.S. capabilities in AI, Altman replied, “It’s hard to say how far ahead we are, but I would say not a huge amount of time.” He said he believed that models from OpenAI, Google and others are the “best models in the world,” but added that to continue winning will require “sensible regulation” that “does not slow us down.”
³¹ For example, Yann LeCun, the chief AI scientist at Meta, has said of AI existential risk: “That’s complete B.S.”
³² For a fuller discussion of the incentives to deploy potentially misaligned AI, see section 5 of Carlsmith’s draft report into existential risks from AI.
³⁴ Some people have raised concerns that by working on some of the technical approaches to the problem listed below, you might actually increase the risk of an AI-related catastrophe.
One concern is that advancing techniques which make AIs safer in important ways — say, better at understanding and responding to humans’ needs — could also make them broadly more capable and useful. Reinforcement learning with human feedback may be one such example.
Since more capable and useful systems are generally better products, market incentives might already be enough to drive this kind of work forward. If so, we’ll probably receive the safety benefits of these techniques eventually, regardless of whether you decide to dedicate your career to advancing them.
By investing additional efforts into these strategies, you might be helping us get these safety benefits a bit sooner — but at the same time, you’ll be accelerating the development of more capable AIs, and ultimately reducing the amount of time we have to understand and mitigate their risks. Your work might also have other downsides, like presenting information hazards.
We don’t think this concern applies to all technical AI safety work. Some of the approaches above are likely to enhance AI capabilities more — and therefore pose greater risks — than others.
Beth Barnes discussed in her appearance on our podcast the argument that, for example, work on AI evaluations could be risky. We also cover related concerns in our article on working at an AI company.
³⁵ There have been lots of efforts to map out the landscape of technical AI safety approaches, though none seem to be exhaustive. You can look at DeepMind’s breakdown of its misalignment work and this overview of the technical AI safety field for more.
³⁶ Notably, it seems reinforcement learning with human feedback has also led to some deceptive behaviour in AI systems — so efforts to use this method to prevent power-seeking might backfire.
³⁷ AI systems might become so advanced that humans can no longer directly evaluate their outputs. To understand how challenging it might be to maintain control in this situation, just imagine your dog trying to train you to behave in the ways that it wants you to.
However, if we can find good ways to supervise AIs that are smarter than us, we can still prevent them from acting against us.
³⁸ For more details about AI system evaluations, you can review the work of the UK AI Security Institute and METR.
³⁹ It’s currently contested how useful mechanistic interpretability will be for keeping advanced AI systems safe.
For the pessimistic case about interpretability tools, see Interpretability Will Not Reliably Find Deceptive AI by Neel Nanda, a leading interpretability researcher, or The Misguided Quest for Mechanistic AI Interpretability by Dan Hendrycks and Laura Hiscott.
For a more optimistic case on the promise of interpretability work, see The Urgency of Interpretability by Dario Amodei.
⁴⁰ Buck Shlegeris discussed AI control methods in detail in his appearance on our podcast.
⁴¹ Researchers reported:
In this trial, the availability of an LLM to physicians as a diagnostic aid did not significantly improve clinical reasoning compared with conventional resources. The LLM alone demonstrated higher performance than both physician groups, indicating the need for technology and workforce development to realize the potential of physician-artificial intelligence collaboration in clinical practice.
⁴² For example, Elliot Thornley has proposed methods for limiting the time horizon over which an AI system has preferences. This would theoretically allow the system to be shut down if it’s behaving in undesired ways. See more here.